В 14 раз быстрее: как Manticore переделал ONNX-путь для embeddings
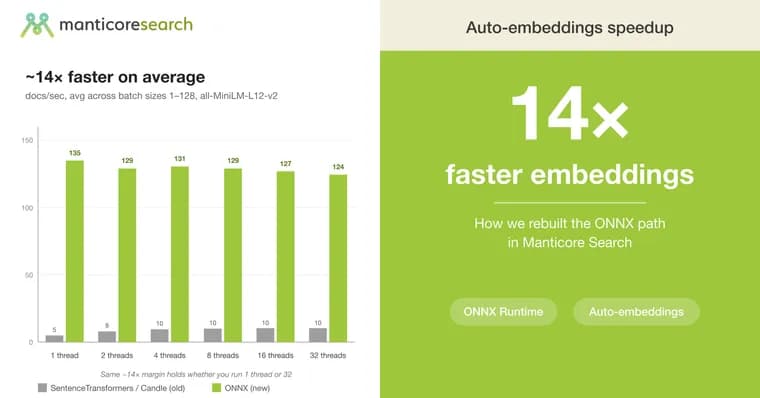
Когда в Manticore появилась функция Auto Embeddings (автоматическое преобразование текстовых колонок в векторы, работающее внутри базы без отдельного ML-сервиса), основная критика касалась скорости. Старая реализация использовала SentenceTransformers поверх Candle (ML-фреймворка Hugging Face на Rust), что приводило к узким местам: большинство рабочих нагрузок давали только 5, 11 документов в секунду, а параллельные запросы сериализовались на одной сессии модели. Инженеры Manticore потратили несколько недель на переделку ONNX-пути. ONNX (Open Neural Network Exchange), это портативный формат, который уже используют популярные модели (MiniLM, BGE, E5 и другие). Новый бэкенд на базе ONNX Runtime (официального, оптимизированного на C++ движка от Microsoft) выпустили в Manticore Search 27.1.5. На одном и том же оборудовании (16 ядер / 32 потока), одной модели (all-MiniLM-L12-v2) и одинаковых весах ускорение составило примерно 14 раз в среднем по полной сетке потоков и размеров батчей. Старый путь держался в диапазоне 5, 11 docs/sec, новый, в 70, 230 docs/sec, и это преимущество сохраняется от 1 до 32 потоков клиента. На однопоточном INSERT задержка упала до 14 ms (с одним клиентом) и 56 ms при восьмикратной параллельной нагрузке; раньше Candle давал 200+ ms. Для максимальной пропускной способности рекомендуется большой размер батча (32, 128) на одном потоке клиента: новый бэкенд параллелизируется внутри вызова, поэтому параллелизм со стороны клиента только добавляет координационных издержек. Пиковое значение на тестовом оборудовании, 233 docs/sec при одном потоке и batch=64. Два изменения дали наибольший эффект: отключение intra_op_spinning (busy-waiting между вызовами) и отказ от батчинга документов внутри воркера. API-интерфейса для пользователя не изменилось: таблица, которая уже указывает на ONNX-модель, автоматически получает новый быстрый путь. Переключение на другую модель требует более сложных манипуляций, Manticore не позволяет менять MODEL_NAME в FLOAT_VECTOR-колонке на месте, но пересоздавать всю таблицу не нужно: можно добавить новую колонку с новой моделью, пересчитать embeddings и удалить старую.
Ключевые факты
- 14-кратное ускорение: с 5, 11 до 70, 230 документов в секунду на том же оборудовании (16 ядер) и модели
- Выпущено в Manticore Search 27.1.5, автоматическое применение к таблицам, указывающим на ONNX-модели
- Два ключевых открытия: отключение intra_op_spinning в ONNX Runtime и отказ от батчинга документов внутри воркера (вопреки учебному подходу)
- ONNX Runtime (Microsoft) используется для pre-fused моделей, которые большинство популярных embedding-моделей уже публикуют
- Асимметричная архитектура: однопоточный INSERT без спавна потоков (быстро), массовый REPLACE INTO со спавном воркеров (параллельно), дешёвое остаётся дешёвым, дорогое, параллельным
Почему это важно
Auto Embeddings встроили в базу, но это означает, что каждый INSERT требует вычисления embeddings. Скорость вставки напрямую определяется скоростью embedding-вычисления, и это становится узким местом. Старый путь через SentenceTransformers и Candle впустую расходовал процессорное время: даже с максимальной параллелизацией и батчингом база не выходила из диапазона 5, 11 docs/sec. Это не позволяло использовать вычислительные ресурсы сервера и замораживало ingest-пропускную способность. Оптимизация, критична для практического использования Auto Embeddings на больших объёмах.
Кому это важно
Разработчикам, использующим Manticore Search для семантического поиска по текстам: RAG-системы, рекомендации, поиск по синониму или смыслу. Особенно тем, кто загружает большие объёмы текстов в реальном времени (например, индексирование логов, архивов, новостей, пользовательского контента). Для приложений с редкой вставкой большой пакет данных выигрыш может быть не заметен, но для continuous ingestion (потоковая подписка, краулинг) разница между 11 и 230 docs/sec, на порядок меняет достижимый SLA.
Как это применить
Обновиться на Manticore Search 27.1.5 или новее. Таблицы, которые уже используют ONNX-модели (например, указывают на модель через .onnx-файл из Hugging Face), автоматически получат новый быстрый путь при следующем INSERT без смены конфига. Если модель на ONNX уже загружена, переключение неявное. Чтобы переключиться на новую модель: добавить новую FLOAT_VECTOR-колонку с другой моделью, пересчитать embeddings для неё, удалить старую колонку. Прямое изменение MODEL_NAME в существующей колонке не поддерживается.
Можно ли доверять
Это подробный технический отчёт команды Manticore с воспроизводимыми тестами: полная матрица потоков × размеров батчей (1 / 2 / 4 / 8 / 16 / 32 потока × батчи 1, 128) на одном оборудовании. Модель (all-MiniLM-L12-v2) и веса, фиксированные, одинаковые для обоих путей, бенчмарки, на одном CPU. Авторы обсуждают неожиданные результаты (почему батчинг вреден) и ошибки в процессе (отказалась от версии на пуле сессий). Нет стороннего аудита, но уровень детализации и честность в описании ошибок вызывают доверие.
Риски и подводные камни
На Windows ONNX Runtime имеет известные проблемы с потокобезопасностью, поэтому там используется Mutex (сериализация вызовов), а на Linux/macOS, прямой доступ без лока. Контринтуитивный результат: батчинг документов вреден из-за padding (если в батче один документ на 60 токенов и семь на 8 токенов, модель вычисляет 8×60 работу вместо суммы реальных длин). На однодокументных INSERT лучше без батчинга, чем с. Это требует изменения интуиции, и легко ошибиться в собственной оптимизации. Смена модели требует манипуляции колонками (не один ALTER TABLE). На нагруженных системах spinning в ONNX Runtime может почти полностью заблокировать CPU другим компонентам (токенизатор, HNSW-индекс), потребляя 100% на очередь между вызовами, требует явного отключения.
«ONNX Runtime (или ORT, официальный оптимизированный на C++ движок Microsoft для ONNX-моделей) делает слияние графов, свёртку констант, автоматическую настройку ядер вычисления. Большинство популярных embedding-моделей на HuggingFace уже публикуют предварительно оптимизированный model.onnx в своей onnx/директории. На диске файл уже в форме, которую ждёт ORT.»
— блог Manticore Search