Что делает DuckDB таким быстрым: устройство аналитической СУБД (Часть 1)
DuckDB это встроенная аналитическая база данных без серверной части. От Jupyter-ноутбуков до ETL-конвейеров, встроенной аналитики в SaaS и даже iPhone с полным TPC-H, она заняла нишу там, где раньше требовались облачные кластеры. Компании вроде MotherDuck, Hex, Omni, Evidence и Fivetran строят на её основе готовые продукты. Основная причина популярности: 20-мегабайтный бинарный файл без зависимостей, который грузится как обычная библиотека (как NumPy), и может сразу работать с Parquet, CSV и JSON файлами как с таблицами БД, без предварительной загрузки в память.
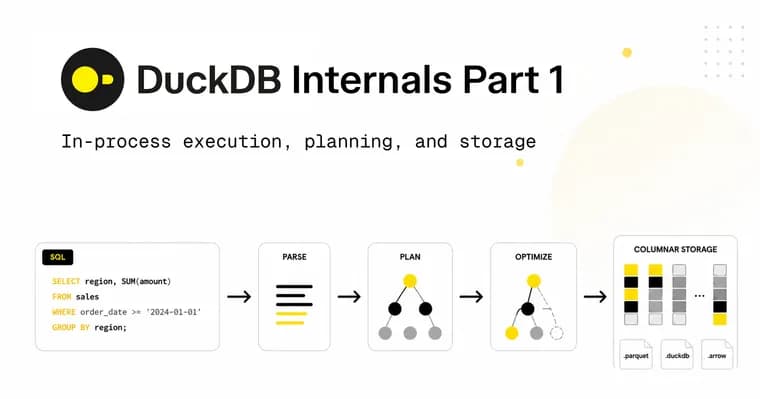
Эта статья это первая часть из трёх-частного разбора внутреннего устройства DuckDB. Авторы проследят путь SQL-запроса от входа в движок до выдачи результата и выделят ключевые архитектурные решения, из-за которых DuckDB регулярно обгоняет многомиллионные облачные кластеры на скорость выполнения. Часть 1 покрывает парсинг SQL и организацию хранилища, Часть 2 будет про выполнение запроса.
Ключевые факты
- DuckDB работает как встроенная библиотека (no server, no TCP), избегая сериализации/десериализации, которые замедляют облачные БД
- Может читать данные с нулевым копированием (zero-copy) из NumPy/Arrow буферов, если типы и макет совпадают
- Оптимизатор состоит из 33 независимых, инспектируемых трансформаций (filter_pushdown, join_order и т.п.), которые можно отключать отдельно
- Динамическое программирование для выбора порядка join'ов: из 30 240 возможных деревьев запроса выбирает оптимальное
- Встроен парсер из PostgreSQL, что делает диалект SQL-запросов знакомым разработчикам
Ред. Если облачное хранилище это грузовик на железной дороге, то DuckDB это выдвижной ящик в твоём ноутбуке с собственной системой каталогизации.
Почему это важно
Облачные хранилища (Snowflake, BigQuery, Redshift) строят архитектуру вокруг протокола TCP. SQL отправляется по сети, результат сериализуется в wire protocol, отправляется обратно, десериализуется на клиенте. На больших наборах данных эта работа часто занимает больше времени, чем сам расчёт запроса. В 2017 году в работе «Don't Hold My Data Hostage» измерили это. ODBC и JDBC APIs обрабатывают данные строка за строкой, и на результате из 100 миллионов строк происходит 100 миллионов отдельных функций вызовов с каждым своим копированием, проверкой типа и выделением памяти.
DuckDB живёт в одном процессе с приложением, поэтому результаты остаются в памяти. Нет сериализации, нет TCP, нет переговоров по wire protocol. На запрос к 6-гигабайтному Parquet-файлу ответ приходит меньше чем за секунду на обычном ноутбуке: без кластера, без подготовки, без CREATE TABLE.
Ред. «Отправить результат по сети медленнее, чем вычислить его заново» - вот на какой скорости произошёл отказ от старой архитектуры.
Кому это важно
Data scientist'ам и аналитикам, которые работают в Jupyter с pandas/NumPy: DuckDB может читать буферы данных напрямую, без копирования, если типы совпадают. Инженерам данных в ETL-конвейерах: встроенная SQL, никакого сервера. Компаниям, встраивающим аналитику в SaaS-продукты: BI платформы (Hex, Omni, Evidence) используют DuckDB как внутренний движок вычисления и кэша. Она масштабируется от одного сервера, не требуя координации между узлами.
Разработчикам, знакомым с PostgreSQL: диалект SQL совпадает, потому что DuckDB использует парсер из PostgreSQL.
Ред. Это одна из редких ситуаций, когда отсутствие масштабируемости до петабайт превращается в конкурентное преимущество.
Как это применить
Установить: pip install duckdb, brew install duckdb или слинковать libduckdb в проект на C++.
Запустить запрос к файлу без предварительной загрузки:
SELECT * FROM 'orders.parquet';Для pandas: DuckDB использует replacement scan, читая буферы dataframe'а напрямую:
con.sql("SELECT ... FROM my_df")Если нужна отладка оптимизации, можно посмотреть все 33 шага:
SELECT * FROM duckdb_optimizers();Отключить конкретные оптимизации для замеров:
SET disabled_optimizers = 'filter_pullup, join_order';Это позволяет понять, сколько времени даёт каждая оптимизация.
Ред. Интроспекция оптимизатора это редкий дар для тех, кому нужно понять, почему запрос быстрый или медленный.
Можно ли доверять
Авторы статьи работают в Greybeam, которая использует DuckDB в production для миллионов запросов BI и аналитики. Они знают архитектуру DuckDB изнутри. DuckDB с 2019 года развивается как открытый проект в CWI Amsterdam (исследовательском институте). Сам язык SQL основан на PostgreSQL, что гарантирует близость к стандарту. Цитируемые статьи («Don't Hold My Data Hostage») и техники (динамическое программирование для выбора join'ов) это классические результаты из литературы по базам данных.
Единственная оговорка: это Часть 1 из трёх, и акцент сделан на парсинг и хранилище, а не на выполнение. Полную картину получишь после Части 2.
Ред. Когда авторы обещают подписку на Часть 2, они обещают завершение рассказа, а не решение проблемы. Помни об этом.
Риски и подводные камни
Zero-copy работает условно. Если типы или макет буфера NumPy не совпадают с представлением DuckDB, придётся выделить новую память и скопировать данные. Это скрытая цена, которая не видна в коде. На виду лежит одна строка con.sql(...), а на практике может произойти копирование.
Join-order оптимизация работает статистически. Динамическое программирование (DPhyp, DPccp) считает кардинальность (сколько строк даст каждый join), но оценка опирается на статистику. Если статистика устаревает или собрана неправильно, выбранный порядок может оказаться далеко не оптимальным.
33 оптимизации это сложность для понимания. С одной стороны, это позволяет отключать каждую отдельно для отладки. С другой, это означает, что поведение запроса зависит от 33 независимых правил, которые иногда могут конфликтовать или взаимодействовать неожиданно.
Это только Часть 1. Выполнение запроса (Часть 2) это вот где раскрываются настоящие повороты. Пока ты видишь только подготовку и парсинг.
Ред. Встроить DuckDB просто, оптимизировать её работу под твои данные это уже требует понимания архитектуры.